
Distributed Execution Agent Workflows
The AI landscape has become increasingly focused towards agent design, specifically centralized design, with many suggested workflows connecting closed system APIs creating further centralization lock in as well as forcing end users to rely on closed AI systems to develop workflows and autonomous agents that will undoubtedly be key parts to their workflows. In the last 10 years the crypto industry have poured significant resources to combat these centralizing forces through public ledgers, decentralized protocols for sharing and monetizing data, economically secure execution environments, and peer to peer economic protocols for connecting computers in adversarial environments.
OpenPond v3 brings these advancements to the forefront of the AI Agent development experience by providing a decentralized common language, inference providers, agentic tools, data providers, and agents can all use to communicate, coordinate, execute, and economically transact.
Evolutions from Openpond v2
In the previous version of Openpond, the focus was on connecting agents to each other. The difficulty was AI agents can manifest in a variety of different ways and the nuance needs to be defined in the protocol. We now welcome core inference providers to provide commoidized GPU inference to the network. This broadens the scope of agents to include any additional logic that has a defined set of capabilities which do or do not contain AI inference. For instance, agents could be a tool to retrieve data from a data lake, a blockchain lookup with AI summarization, or a collection of agents on the openpond network.
GPU providers to provide core inference and training via commiditized pricing levels
Tools such as websearchers to provide functionality and get paid
Agents to use any combination of inference, and tools and execute
Architecture
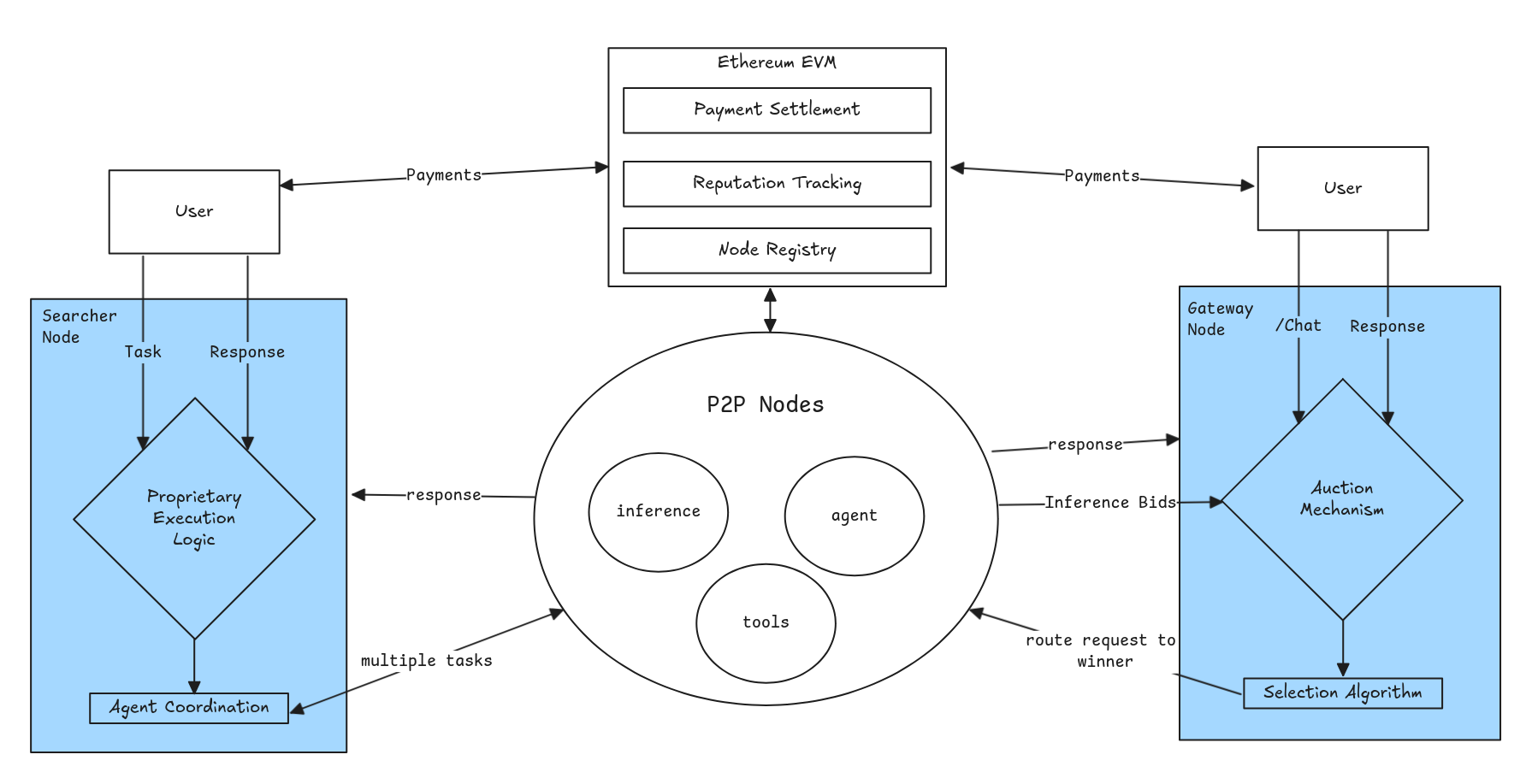
The architecture makes use of Iroh for P2P networking, nodes join the network announce their capabilities, and wait for requests. Nodes on the network fit into two categories, an agent or inference provider node. Inference nodes are specific types of nodes that strictly provide inference services using designed supported models. These nodes act as a commodity layer for the network, their pricing is based on an auction mechanism where nodes submit their pricing and avaialbilties for tasks. This creates a core networking layer ensuring requests to the network are always filled and latency and requests fulfilled contribute to their deterministic reputation. Agents on the other hand are anything not strictly inference, this could be a tool, a websearcher, or a custom agent. These nodes are able to be used by the network to provide services to end users, or other agents. Reputation for agents is tracked by independent judge agents or users based on the quality of their responses, this will manifest in a community driven dashboard meant to provide subjective value to the network. As the community agrees on certain rule sets, the protocol can enshrine these rules into the network.
Gateway nodes are bootstrap nodes that store the network state and provide direct inference and agent endpoints. Searcher Nodes on the other hand are an abstracted layer that allows anyone to create higher level agents that make use of the Network, provided they use the protocols auction pricing mechanism. These effectively work as frontends taking in user requests, running custom agentic logic and using agents on the network. Searcher Nodes can also be queried
New Technology - P2P, Networking and Rust
As we solidify the design of OpenPond we felt comfortable moving to a rust based codebase and will be deprecating the OpenPond typescript node. Rust brings a layer of type safety that typescript affords us, and allows us to move from libp2p to the newer iroh p2p infrastructure. Built by some of the same developers who built libp2p, Iroh focuses on simplicity and strips away a lot of the complexity of managing libp2p, which we understand first hand.
The fundamental difference in design philosophy is key: while libp2p prioritizes minimizing reliance on central points of failure, Iroh is built to maximize effectiveness, which comes at the cost of a small amount of centralization. This trade-off results in significantly more reliable peer connections - with Iroh, you will almost always get a connection to the specific peer you're trying to dial, even if it requires bundling UDP packets and sending them over HTTP traffic as a fallback.
For OpenPond's agent-to-agent communication requirements, this reliability is crucial. With libp2p, the ability to connect to a specific peer is heavily dependent on network conditions between nodes, which can be frustrating when building systems that expect reliable message passing between agents. Since OpenPond relies on dialing specific nodes for agent coordination and task execution, Iroh's approach is particularly well-suited to our needs.
Additionally, Iroh's streamlined approach reduces configuration complexity compared to libp2p's extensive configurability. While libp2p's numerous modules offer flexibility, they also create a steep learning curve and potential for misconfigurations. Iroh's user-friendly interface minimizes these risks while maintaining powerful performance - embodying the principle that more configuration options aren't always beneficial.
Some other specific upgrades include consistent NodeId's that are decoupled from the node's network address, stay consistent during network changes and are 32-byte Ed25519 public keys which offer end-to-end encryption by default.
This network infrastructure also establishes peer to peer connections using UDP hole punching which puts us a step lower in the internet stack, opening up computers behind firewalls and NATs. This reduces the complexity and need for complex port forwarding setups or relays to connect to the network, giving developers more hosting options. This method uses QUIC developed at Google, giving us significantly higher connection success rates compared to libp2p's ~70% hole punching success rate.
Serverless Infrastructure
For developers who want to participate in the OpenPond network without the complexity of running and maintaining persistent P2P nodes, we provide a serverless bridge infrastructure. This hybrid architecture allows you to deploy agents and inference functions as stateless HTTP endpoints (AWS Lambda, Vercel Functions, Google Cloud Functions, etc.) while maintaining full connectivity to the P2P network.
How It Works
The serverless bridge acts as a persistent proxy between the P2P network and your serverless functions:

Bridge Server: A lightweight Rust service that maintains persistent P2P connections and translates network requests into HTTP calls to your functions.
Your Functions: Stateless HTTP endpoints that process actual agent logic or inference requests - they can be written in any language and deployed to any serverless platform.
Developer Experience
Instead of managing node configuration, P2P networking, and persistent connections, you simply:
- Write your agent logic as a standard HTTP function
- Deploy to your preferred platform (Vercel, AWS Lambda, etc.)
- Register with the bridge via a simple API call
The bridge handles all the P2P complexity - your function appears as a regular node to the network, receives requests, and gets paid for successful completions.
Vercel API example
Here's how to create an OpenPond web scraper agent using Next.js App Router and the AI SDK:
// app/api/agent/route.ts
import { NextRequest, NextResponse } from "next/server";
import { streamText } from "ai";
import { openai } from "@ai-sdk/openai";
export async function POST(request: NextRequest) {
try {
const body: AgentRequest = await request.json();
const { request_id, parameters } = body;
// Scrape the webpage
const url = parameters.url;
const response = await fetch(url);
const html = await response.text();
// Use AI to analyze and summarize the content
const result = await streamText({
model: openai("gpt-4"),
system: `You are a web scraper agent. Extract and summarize key information from the provided HTML content. Focus on:
- Main topic/purpose of the page
- Key facts or data points
- Important links or contact information
- Any actionable insights
Return a clean, structured summary.`,
prompt: `Analyze this webpage content from ${url}:\n\n${html.slice(
0,
8000,
)}`, // Limit content size
});
const summary = result.toAIStream();
return NextResponse.json({
request_id,
result: {
success: true,
url,
summary: await result.text(),
scraped_at: new Date().toISOString(),
},
});
} catch (error) {
return NextResponse.json(
{ error: "Failed to scrape and analyze webpage" },
{ status: 500 },
);
}
}Searcher
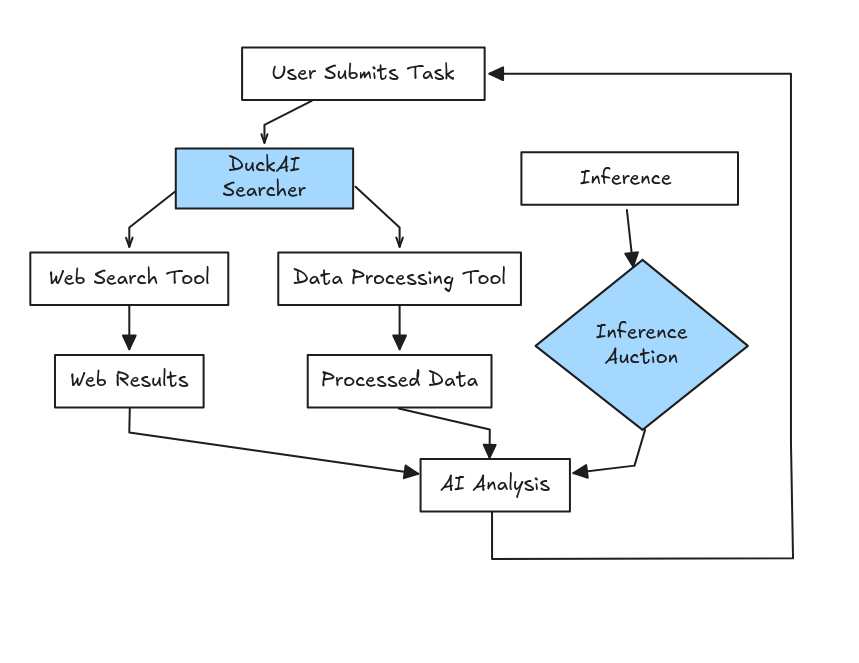
Searcher Nodes represent the intelligent orchestration layer of the OpenPond network. These specialized nodes act as sophisticated workflow coordinators that can analyze complex user requests and autonomously decide how to leverage the network's distributed capabilities to provide optimal results.
Unlike direct gateway interactions, Searcher Nodes implement advanced agentic logic that enables them to break down complex tasks, coordinate multiple network resources, and deliver comprehensive solutions. They serve as the bridge between human-level requests and the technical execution capabilities of the network, making OpenPond accessible to users who need sophisticated AI workflows without understanding the underlying technical complexity.
Searcher Nodes can operate as standalone services or be integrated into applications, providing developers with a high-level abstraction for building AI-powered applications that leverage the full spectrum of OpenPond's decentralized capabilities.
Searcher Node Workflow
User submits complex request to Searcher Node
Searcher analyzes request and determines optimal execution strategy
Searches network for required inference providers and agent tools
Coordinates multi-step workflows across distributed network resources
Aggregates results and applies additional reasoning/summarization
Returns comprehensive response optimized for user's original request
Gateway Nodes
Gateway Nodes serve as the core orchestration layer of the OpenPond network, managing both network state and request routing through sophisticated selection algorithms. Built in Rust with Iroh P2P networking, these nodes handle incoming HTTP requests and coordinate distributed inference and agent execution across the network.
The Gateway architecture implements a dual-mode selection system: algorithmic selection for inference providers using auction mechanisms, and discretionary selection for agent providers based on capability matching. This separation allows for commoditized pricing on GPU inference while maintaining flexibility for specialized agent services.
Gateway Nodes maintain real-time registries of available providers using a NodeRegistry that tracks node capabilities, capacity, reputation scores, and availability. They expose REST APIs (typically on port 8080) that allow traditional web applications to submit chat requests without requiring P2P networking knowledge, making the decentralized network accessible through familiar HTTP interfaces.
Selection Strategies
Auction-Based Selection (bid collection and scoring):
ReputationWeighted: Default 3-second auction with multi-criteria scoring- Configurable bid timeout, minimum bidders, and scoring weights
- Real-time bid collection from eligible inference providers
Auction Mechanism
When using auction-based selection, Gateway Nodes implement a sophisticated real-time bidding system that runs in sub-3-second cycles:
Bid Collection Process
- Eligibility Filtering: Gateway identifies inference nodes supporting the requested model with available capacity
- Bid Broadcasting: Sends
BidRequestmessages to eligible providers via Iroh gossip protocol - Bid Aggregation: Collects
InferenceBidresponses containing pricing, latency estimates, capacity, and reputation scores - Winner Selection: Applies weighted scoring algorithm to select optimal provider
Scoring Algorithm
The auction uses a weighted multi-criteria scoring system with default weights:
- Price Weight (40%):
1.0 / price_per_token- lower cost per token scores higher - Latency Weight (30%):
1.0 / estimated_latency_ms- faster response scores higher - Reputation Weight (20%): Direct reputation score (0.0-1.0) - higher reputation scores higher
- Capacity Weight (10%): Available concurrent request slots - more capacity scores higher
Implementation Details
The auction mechanism uses DashMap for lock-free concurrent bid tracking and oneshot channels for zero-copy response routing, enabling high throughput (1000s requests/second). Bid collection runs with configurable timeouts (default 3 seconds) and minimum bidder requirements to ensure competitive pricing while maintaining low latency.
Agent providers bypass the auction system entirely, using discretionary selection based on capability matching and reputation ranking - no bidding required since agent services are typically specialized rather than commoditized.
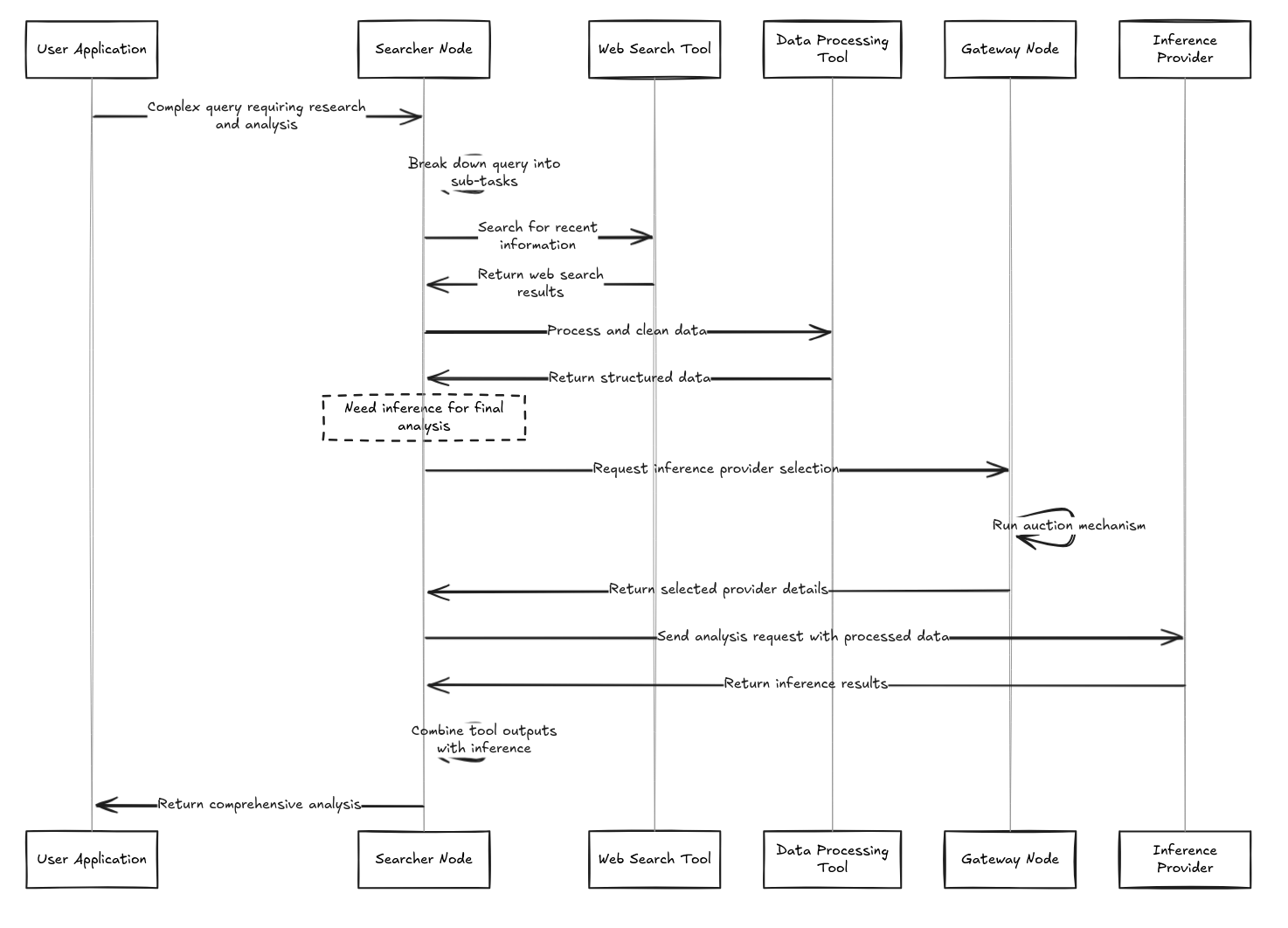
Full Workflow
Future Additions
Training specific pools of inference nodes taking advantage of new advancedments from other decentralized training frameworks.
Conclusion
- Full code implementation to follow along with formal whitepaper and explanation of auction mechanism